RabbitMQ in Aktion: Heute sind wir imgur
Im letzten Artikel habe ich euch erklärt, was RabbitMQ ist und wie man es in einem einfachen Beispiel verwendet. Heute möchte euch die Vorzüge einer Message Queue in einer synchronen Applikation anhand eines Echtwelt-Beispiels verdeutlichen.
Ein toller Vergleich für die Funktionsweise und Einsatzmöglichkeiten von RabbitMQ ist ein Bilder-Upload-Service.
Heute tun wir mal so, als ob wir imgur.com wären, einer der größten Anbieter solcher Dienste.
Give me numbers
Ich habe mal Dr. Google nach Statistiken von imgur befragt und bekam auch Antworten.
Die erste Quelle ist ein AmA (ask me anything) des ursprünglichen Entwicklers auf reddit.com. Die Angaben dort sind bereits einige Jahre alt und leider mehrdeutig, denn einerseits steht dort “August 2014”, andererseits “6 years ago”, was nicht so recht zusammenpasst (for the record: es ist 2018). Wie dem auch sei, laut den Angaben des Entwicklers wurden zu jener Zeit ~20,5 Millionen Bilder in einem Monat hochgeladen.
Die zweite Quelle ist ein Artikel auf venturebeat.com, eine US-amerikanische News-Website. Dem Artikel zu folge wurden 2015 auf imgur täglich 1,5 Millionen Bilder hochgeladen. venturebeat nennt zu dieser Information keine Quelle, aber das Wachstum klingt in Relation zu den Zahlen im AmA zumindest für mich realistisch.
Ich denke man kann davon ausgehen, dass imgur seitdem noch weiter an Reichweite gewonnen hat und noch mehr Uploads pro Tag hat, da das aber reine Spekulation ist, gehen wir von den 1,5 Millionen aus der zweiten Quelle aus. Beachtliche Menge. Runter gerechnet sind das rund 18 Bilder pro Sekunde.
Mindestens vier verschiedene Versionen eines Bildes konnte ich auf den Seiten finden:
- das Originalbild
- zwei quadratische Thumbnails mit unterschiedlichem Ausschnitt
- sowie die Normalansicht, auf Breite skaliert
Wenn also pro Sekunde 18 Bilder hochgeladen werden, bedeutet das, dass insgesamt pro Sekunde 54 weitere Versionen der Bilder generiert und insgesamt 72 Dateien im Dateisystem abgelegt werden müssen. Wir sprechen hier übrigens vom Durchschnittswert, zu Stoßzeiten wird vermutlich ein vielfaches hiervon produziert.
Pragmatisch …
Gehen wir von einer für eine PHP-Applikation naheliegenden, naiven Vorgehensweise aus:
Ein User löst auf unserer Webseite einen Upload-Request aus, welcher unsere Applikation triggert. Auf die eine oder andere Weise fangen wir an, die drei weiteren benötigten Bildergrößen zu generieren und zusammen mit dem Original abzuspeichern. Wenn all die Arbeit erledigt ist, bekommt der User eine Rückmeldung.
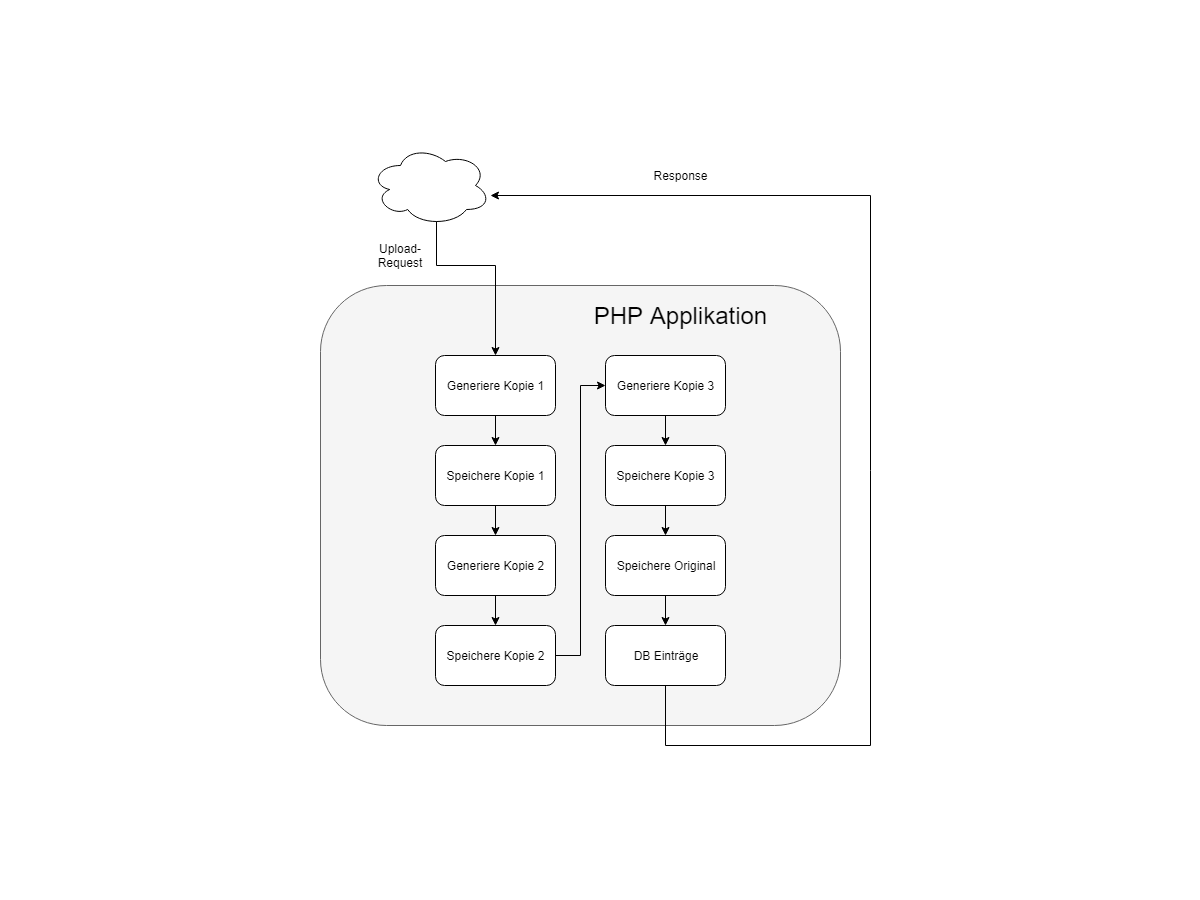
Die folgende Grafik stellt einen solchen Ablauf ganz grob dar. Es geht hierbei nicht um die Details, sondern um den reinen Ablauf vom Request bis zur Response.
… und problematisch
Noch sieht dieses Schaubild nicht all zu daneben aus. Die Probleme kommen vor allem mit etwas Last. Wenn wir uns nun vorstellen, dass dieser Ablauf ganze 18x pro Sekunde aufgerufen wird, werden wir in der Praxis feststellen, das die Laufzeit der einzelnen Applikationsdurchläufe sich erhöhen wird. Auch die Skalierung der Hardware wird ab einem gewissen Punkt schwierig. Im schlimmsten Fall müssen User immer länger auf eine Antwort im Browser warten.
Wie hilft uns jetzt RabbitMQ?
Tatsache ist doch, dass es den User überhaupt nicht interessiert, ob der Service für seine Zwecke das Bild in weiteren Formaten benötigt. Als User möchte ich eine schnelle Rückmeldung, sobald mein Bild erfolgreich angenommen wurde und man mir eine URL anbieten kann.
Daraus können wir schließen, dass nur ein kleiner Teil der Arbeit (das Archivieren und Katalogisieren des Originalbilds) sofort erledigt werden muss, damit wir dem User antworten können. Der aufwändigere Teil (das Erstellen der Thumbnails) kann getrenn ablaufen und muss kein Feedback an den User liefern.
Das Ganze könnte dann ungefähr so aussehen:
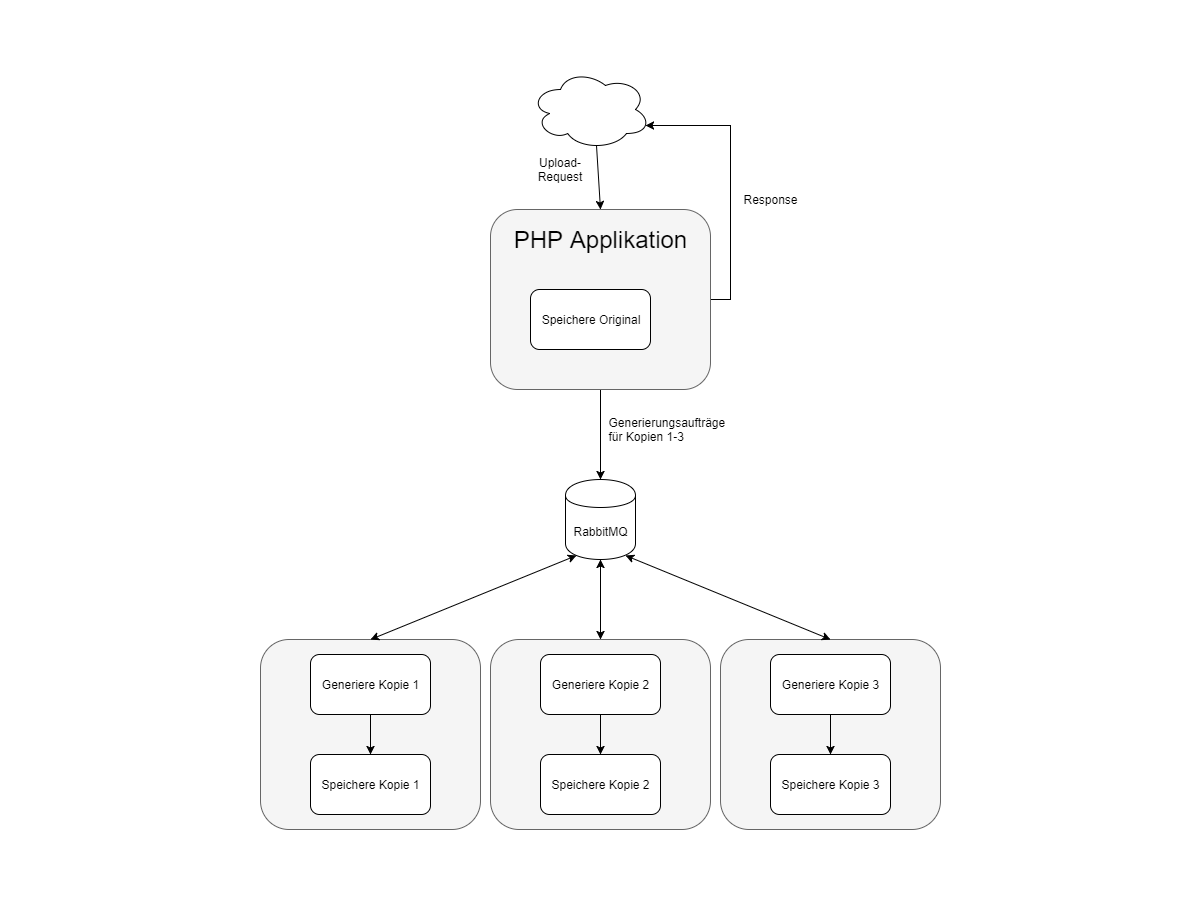
Die Bilder im Hintergrund generieren
Jetzt brauchen wir vorne nur eine kleine Applikation, welche das Originalbild annimmt und ablegt. Außerdem erzeugt sie Nachrichten für Worker im Hintergrund, welche dann nach und nach die Kopien erstellen können. Der Status dieses Prozesses ist für den User uninteressant, er wird schon früher benachrichtigt.
Wer aufgepasst hat, sieht hier eine kleine Microservice-Architektur. Wir haben unseren großen Monolithen in kleine Services aufgeteilt, was auch hinsichtlich der Skalierung ein Gewinn ist, denn nun können wir viel flexibler mit Hardware (oder - ganz trendy - mit Containern) umgehen.
Dieses Beispiel zeigt, wie uns Messaging Queues helfen können, stark synchrone Applikationen etwas flexibler zu gestalten, indem wir unsere Applikation in logische aber unabhängige Blöcke aufteilen, und diese dann mit einander kommunizieren lassen.